Probability as normalised proportionality
Probabilities are just weights. Normalised to sum to unity. No negative weights are possible. Any time you can assign some number $P(i)$ to a set of $n$ objects/events/occurrences, finite or infinite, such that $\sum_{i=1}^n P(i)=1$. It is a world of weights with lower bound 0 and upper bond 1. Mathematically those probabilities don't have to mean anything. They don't have to correspond to real world probabilities. They just need to be a collective set of non-negative numbers which sum to 1. That's it. If the set of numbers have that, it is a proper probability. How best to formally define this? Make the objects be sets.
Sets are a useful ontology for mathematically approaching normalised proportionality
First, set your universe. This is the set of all possible elementary (i.e. disjoint) outcomes. In any experiment, precisely one of these elementary outcomes will occur. So the probability of an elementary outcome occurring, but where we don't care which, is 1. We call the superset of all these disjoint elementary outcomes the sample space, often $S$. If we want to refer to 'impossible' then this corresponds nicely to the probability of the empty set, $P(\{\})=0$, which gives us our floor.
Core axiom of probability - union/addition of disjoint events.
The engine which drives all of the basic theorems of elementary probability theory is in effect a definition of the word disjoint in the context of probability.
$P(\bigcup_{j=1}^{\infty}A_j) = \sum_{j=1}^{\infty} P(A_j)$. In other words, if you want to know the combined total probability of a union of disjoint events, go ahead and just sum their individual probabilities. So, as you can see, if we define an experiment as just the sum total of elementary outcomes (disjoint), then naturally, this full sum will result in 1. This is the probabilistic version of 'something is bound to happen'.
Already, with this core axiom, together with the floor and ceiling statements - the statements of proportionality, namely $P(\{\})=0$ and $P(S)=1$, we can derive/define the following. In what follows, our main trick is to see if we can define arbitrary events in ways which are disjoint. We need to get to that point so that we can be justified in triggering the core axiom. So we smash, smash, smash sets until we have a collection of homogeneously disjoint sets. This allows us free reign in applying the core axiom.
Let' see how the two set theory terms, complementarity, $A^c$ and proper subset $\subseteq$ ought to work in probability.
Complementary sets $A$ and $A^c$ are already disjoint, so immediately we know that we can treat $P(A \cup A^c) $ using the core axiom, plus by definition of complementarity, $P(A \cup A^c) =1$. This gives us $P(A) + P(A^c) =1$ and so $P(A^c) = 1 - P(A)$. This is often a great problem solving tool since we may find it easier to find the probability of an event's complement than directly of the event itself. A classic example is the
birthday problem.
Now let's work on an inequality. If $A \subseteq B$ then $P(A) \leq P(B)$. This is our first non-trivial case of 'smash smash smash'. $A$ is inside $B$, which suggests that we can smash $B$ as the union of $A$ and, ...., something else. Something disjoint to $A$. How about $A\cup (B \cap A^c)$. Now, $P(B)$ becomes $P(A\cup (B \cap A^c))$, and by the power of our core axiom, this is equivalent to $P(A) + P(B \cap A^c)$. Our floor axiom tells us that no probability can be less than 0, so $P(B \cap A^c) \geq 0)$ and hence $P(B) \geq P(A)$. This little inequality points in the direction of
measure theory.

Knowing how to rank the probabilities of any given set in the probability space is a useful thing to know, but having to power to do addition is even better. How can we generalise the core axiom to cope with sets which are not guaranteed to be disjoint? Think of your classic two-sets-with-partial-overlaps Venn diagram. If we want a robust calculus of probability, we need to crack this too.
In general, we just need to be more careful not to over-count the shared areas. Here it should be clear that there is a 'smash smash smash' decomposition of the areas in this diagram into pieces which are properly disjoint. And indeed there is. Skipping on the details, we arrive at $P(A\cup B) = P(A) + P(B) - P(A \cap B)$. This two case example of making sure you count each disjoint area precisely once, by adjusting, generalises to: $P(\bigcup_{i=1}^{n} A_i) $ can be represented as $\sum_i P(A_i) - \sum_{i<j} P(A_i \cap A_j) + \sum_{i<j<k} P(A_i \cap A_j \cap A_k) - \ldots + (-1)^{n+1} P(A_1 \cap \ldots A_n) $. Think of this as the mathematical equivalent of an election monitor who is trying to ensure that each voter only votes once.
So now we have the addition of any events $A_i$ in the probability space. Sticking with the voting analogy, we will now drop down from a level of high generality, to one where all elementary outcomes are equally probable. Imagine an ideal socialist, hyper-democratic world with proportional representation. As we have seen, we already have the election monitor who endures the technical validity of summation. But in this political environment, we want each elementary outcome (voter) to cast a vote which is precisely the same weight as all other voters. We also measure utility in the ruthlessly rational-sounding utilitarian way - namely that we decide on our political actions by asking the people, and counting their votes equally. In this less general world, simply counting the number of votes for any given event is all we need to do, since all votes are worth the same as each other. Once we have the counts, we can stop, since we can now create count-based probability distributions. Here we're in the world of fair dice, well shuffled playing cards, randomly selected samples. And for those problems, combinatorics helps.
Let's assume there's an experiment with $n$ elementary outcomes and some event $A$ can happen in $p$ of those. then $P(A)$ can be measured as $p/n$.
Multiplication rule - chaining experiments
Imagine you could perform an experiment with $n$ outcomes as often as you like, with precisely the same set of outcomes each time. That is, the second performance of the experiment has no 'memory' of the first result. Technically this property is called a
Markov property. There would be $n$ outcomes on that second experiment. In total there would be $n \times n$ outcomes in the meta-experiment which consisted in doing the first, then doing the second. But your second experiment might be a totally different one, with $m$ outcomes. Nonetheless there would be $n \times m$ possible outcomes now in the new meta-experiment.
Temporal fungibility
Note that, since multiplication is
commutative, it doesn't much matter if you do experiment '2' before experiment '1' - you still get $n \times m$ outcomes. A similar effect occurs when you're adding probabilities - since addition is commutative. This temporal fungibility helps later on with
Bayes' theorem.
Four sampling rules follow from the multiplication rule:
- Sampling $k$ from $n$ with replacement, selection ordering matters: $n^k$
- Sampling $k$ from $n$ without replacement, selection ordering matters: $\frac{n!}{(n-k)!}$
- Sampling $k$ from $n$ with replacement, selection ordering doesn't matter: $\binom{n+k-1}{k}$
- Sampling $k$ from $n$ without replacement, selection ordering doesn't matter: $\binom{n}{k}$
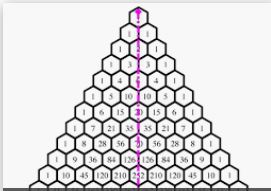
Mirror rule for binomial coefficient. Picking the rejects

When the team captain picks his preferred team, he's also implicitly picking his team of rejects. Another way of saying this is that Pascal's triangle is symmetrical. Another way of saying it is that $\binom{n}{k} = \binom{n}{n-k}$. Again, this is a useful trick to remember in solving combinatoric problems.
L-rule for binomial coefficient

$\sum_{j=k}^n \binom{j}{k}=\binom{n+1}{k+1}$. Or in pictures, all numbers like the number in yellow are the sum of the set of numbers in blue. This collection of blue and yellow numbers is approximately like an L tilted. This provides a useful decomposition or simplification, especially in cases where we have scenarios made up of a sum of binomial coefficients. Cases like this and the below team captain decomposition relate a sum of binomials which in effect partitions the problem space in an interesting way, with a new binomial partition. A partition generally is a complete and disjoint subsetting of the problem space. Here, we imagine one property in the population is rankable (eg age) with no ties. So there is a population of $n+1$ in total and we picked this person to be in the selection group. The partition is as follows: imagine you pick your selection group; find the oldest in your group, and now start asking a series of questions about where this oldest in your group ranks in the overall population. He could be the population oldest. If so, then we define the rest of the group as $\binom{n}{k}$. Perhaps he's the second oldest in the population. If he's the second oldest in the population, then, by definition, we can't have picked the oldest from the population to be in our group (since we already found and identified our own oldest in group), so we know we must have $\binom{n-1}{k}$ other ways to satisfy this condition. Continue along this path and you end up with the L rule.
The greatest. Binary partitions for binomial coefficient

$\binom{n+1}{k} = \binom{n}{k} + \binom{n}{k-1}$. The story here is : one of your population has a unique persistent property. Now you come to chose $k$ from these $n+1$. This is the same as the partition where your pick contains the prize winner and the other partition, where it doesn't.
Two tribes - Zhu Shijie (sometimes attributed to Vandermonde)
$\binom{m+n}{k} = \sum_{j=0}^k\binom{m}{j} \binom{n}{k-j}$. The story: Your entire population is made up of two tribes. You have known sub-populations of each (ie you know the proportion). You now pick your $k$. This is the same as first segregating the populations into 2, then picking some number $j\leq k$ of the first tribe and, using multiplication rule on the second experiment, picking $k-j$ of the second tribe. You run this for all possible values of $j$.
Lentilky. On tap at the factory, in dwindling supply in your pocket.
Forrest Mars, after telling his dad to "stick his Mars job up his ass" because he didn't get the recognition for the invention of the Milky Way, left for Britain in 1932. By 1937, during the Spanish civil war, he was touring Spain with George Harris of Rowntree, they saw off-duty soldiers eating Lentilky, Moravian chocolate shaped like little lenses, covered with candy to stop the chocolate from melting. That idea was created by the Kneisl family, who had a factory in Holešov, making the stuff since 1907. Harris and Mars decided to rip the idea off, and came to a gentleman's agreement to make Smarties in the UK and M&Ms in the USA. Imagine a tube of Lentilky. Each tube contains from 45 to 51 chocolate candies, of which there are 8 colours. So how many possible tubes of Lentilky are there in total. Ignoring for a moment the practical reality of the factory guaranteeing that you get probably roughly the same number of colours in each shape, let's allow all possibilities.
Step 1 in solving this is recognising it as a combinatorics problem. Step 2 concentrates on one of the box cardinalities - say the tube with 45 sweets. Step 3 recognise that this is sampling of $k$ from $n$, with replacement, order unimportant, $\binom{8+45-1}{8}$. More generally, if the number of sweets is $i$, this is $\binom{8+i-1}{i}$. That step is particularly non-intuitive, since $n$ is so much smaller a population than $k$, which you can only do in sampling with replacement. Given they're unordered in the tube, order doesn't matter. Step 4 applies the mirror rule, so that $\binom{8+i-1}{i} = \binom{i+7}{i} = \binom{i+7}{7}$. Why do that step? Well, you've simplified the expression. But $i$ ranges from 45 to 51 of course, so there's a summation going on here: $\sum_{i=45}^{51}\binom{i+7}{7}$. Step 5 simplifies the for range: $\sum_{j=52}^{58}\binom{j}{7}$; Step 6 rearranges to get $\sum_{j=7}^{58}\binom{j}{7} - \sum_{j=7}^{52}\binom{j}{7}$. Step 7 is to use the L-rule, equating this to $\binom{59}{8} - \binom{53}{8}$. My R session tells me the answer is 1,331,148,689 or about 1.3 billion.

Subset cardinality as binary encoding
Consider a set with $n$ members - surely a candidate for one of the most generalised and useful objects in all of mathematics. Free from any representation, not tied down to a semantics. Just $n$ objects. How many subsets of this general set are there? Transform this question into the following recipe for enumerating all proper subsets. Imagine a register with $n$ bits. Each possible value of this register represents precisely one subset by virtue of the first bit being set representing the state that the first object is also in this subset, the second, third likewise. The total number of values for an $n$ bit register is $2^n$, which is also therefore the cardinality of the number of subsets - including the null set and the original set itself.
Survival of the *est
Abstract example. Take that set of $2^n$ subsets of the primordial set of $n$ objects. Which of those has the largest cardinality? Why the set containing all $n$ elements, of course. Of course, only because we have this omniscient perspective on the set of all subsets of $n$. But imagine we have a much more local and limited capacity, namely that we can select 2 of those $2^n$ subsets and face them off against each other. The 'winner' is the largest (or the one which has the highest of any other rankable measure). Imagine we do that for the whole set of randomly chosen ordered pairs. We collect each winner and, just like a knockout tournament, we pair the winners off. We repeat. At the end, the last set standing is the largest, and it will of course be the set of all $n$ objects. This knockout tournament is like a partially functional
merge sort algorithm. The full equivalence is when we let all the losers battle it out too. But back to the tournament. There are $\binom{n}{2}$ initial pairings, there are $n$ rounds in the competition and there are $2^n -1$ actual matches in the whole tournament. The CPU of a computer is precisely such a localised, embodied, non-omniscient actor, and that actor needs an algorithm to achieve what a set-theory God can know merely by intuition. The tournament or natural selection, or markets represent a local-space algorithm which results in a somewhat God-like perspective.
Sequential snap
Again assuming limits to knowledge, let's imagine all $n$ objects in our primordial set have permanently associated integers 1, 2 etc linked with them. Now, again in a very non-set way, let's create a permutation of those $n$ objects. With limited knowledge, we will model the probability that when we examine this permutation, object by object, that the object associated with the integer $i$ will be examined at the $i$th examination moment. The likelihood that you win the game is independent of the value of $n$, rather surprisingly, at $1- \frac{1}{e}$